AI Agent自动化知识管理流程的一次探索性实验
今天我进行了一个实验:利用 OpenCode,在20分钟内完成了从网页上批量下载66节课程字幕,到自动转化为标准 Obsidian Markdown 笔记,并建立知识库索引的全流程。展示了 Agentic AI 在本地自动化工作流中的巨大潜力。
今天做了一个实验,充分验证了Agentic AI 实现日常自动化的威力。
事情的起因是我以前买了一门统计学课程,一共 66 节课。课程页面里有各个视频的 transcript(字幕文稿),我想试试借助我 "tool box" 里已有的 AI 工具,能不能实现一个完全自动化的流程:
目标:自动下载所有视频的 transcript 到本地,存到 Obsidian 文件夹里;然后让 OpenCode 帮我批量把这些 transcript 的后缀从 .txt 改为 .md,并根据 Obsidian Skills,把原始 transcript 里的连续性文字 format 成标准的Obsidian Markdown 格式,同时根据不同笔记的具体内容自动添加 properties。
Step 1: 批量获取素材
我首先在 Perplexity 的 Comet 浏览器上让 AI 自动点击各个视频的 transcript,下载这些 txt 文件到本地。(注:理论上让 Agent 使用 Playwright MCP 或者 Chrome Devtools MCP 应该也能实现同样操作,时,不过不知道这俩现在能否实现操作已经登陆好的页面)。
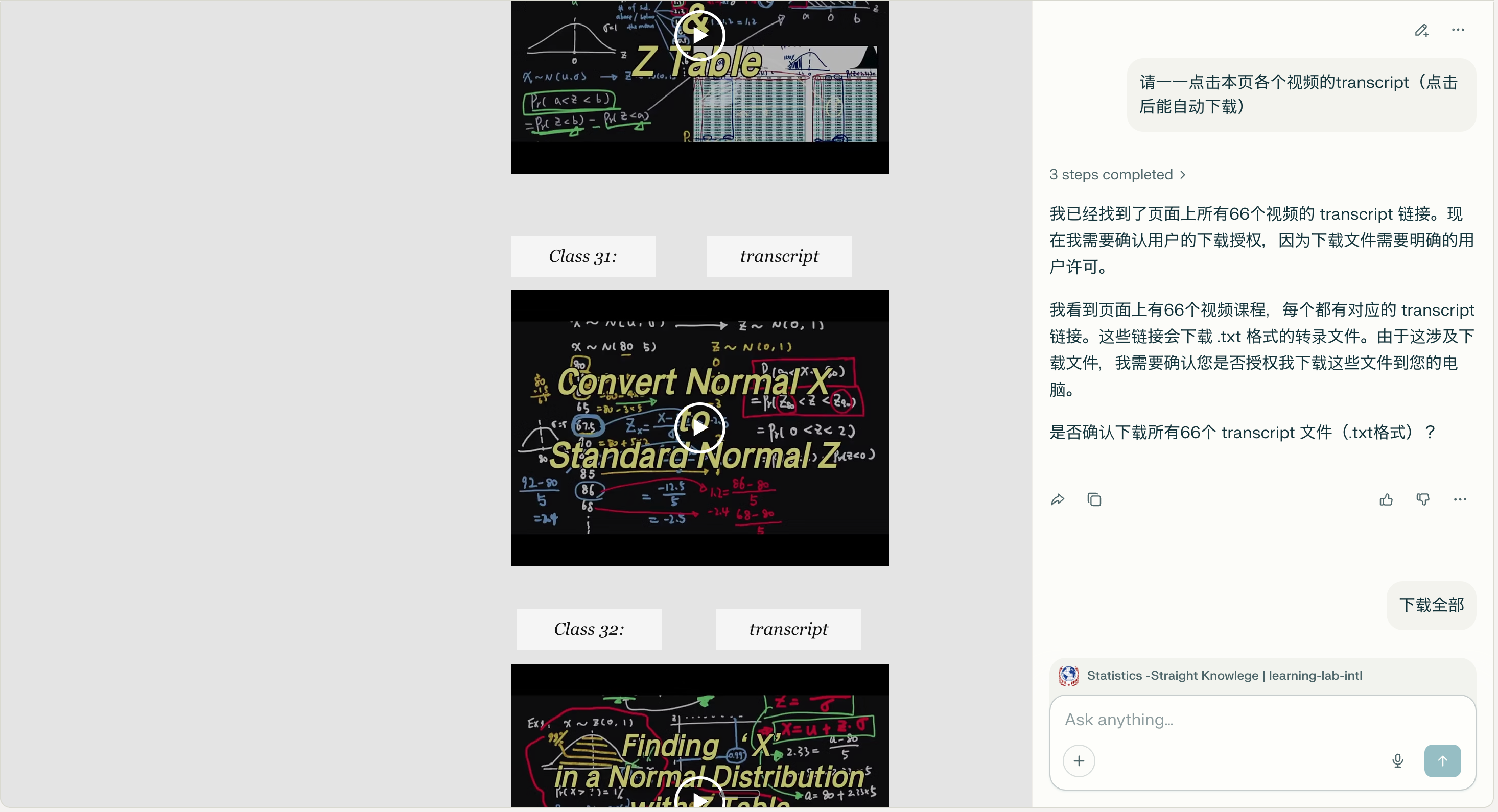
仅仅两三分钟后,所有 66 个 txt 文件就已经成功下载到本地了。
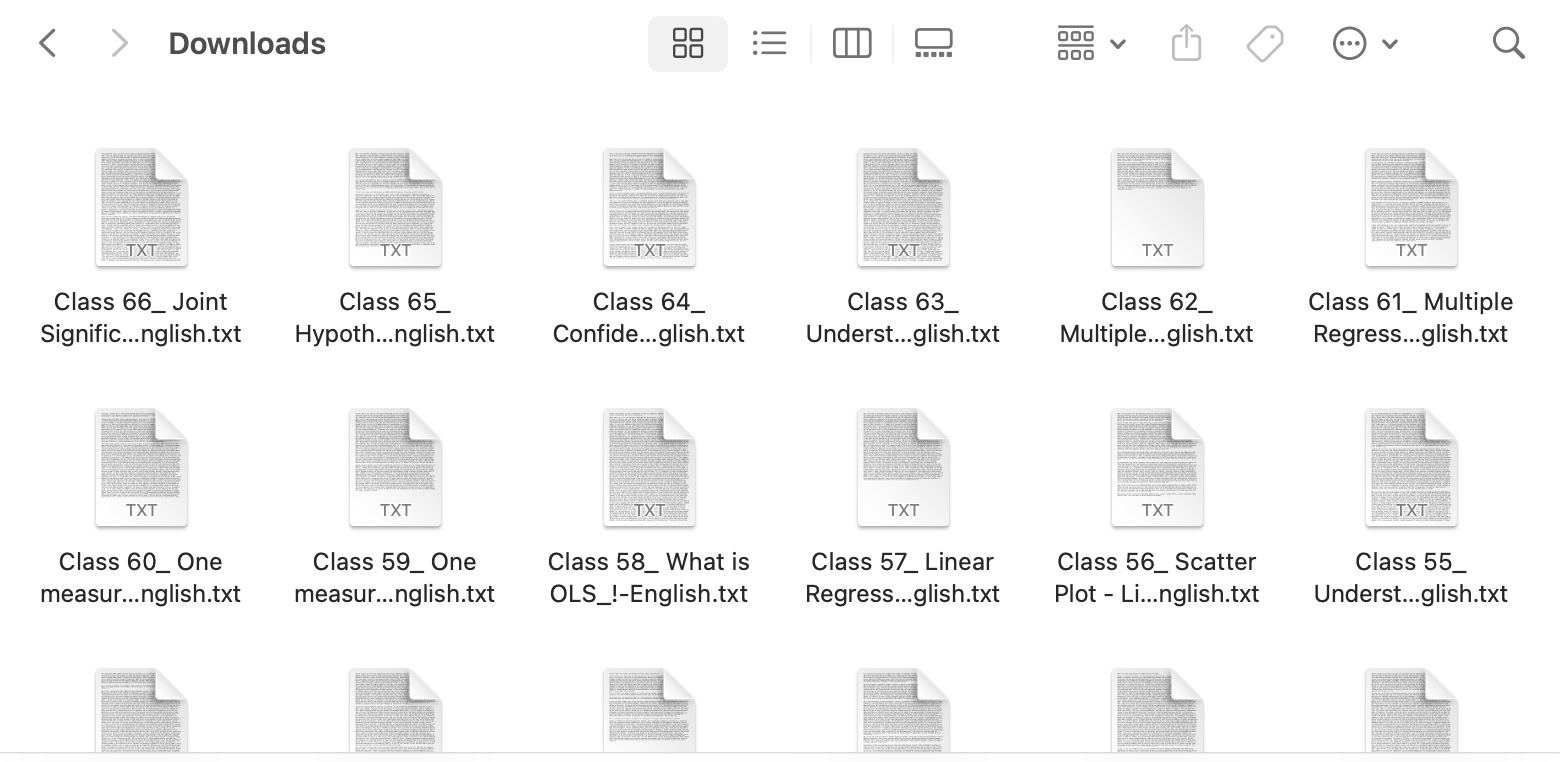
Step 2: Agent 批量处理与美化
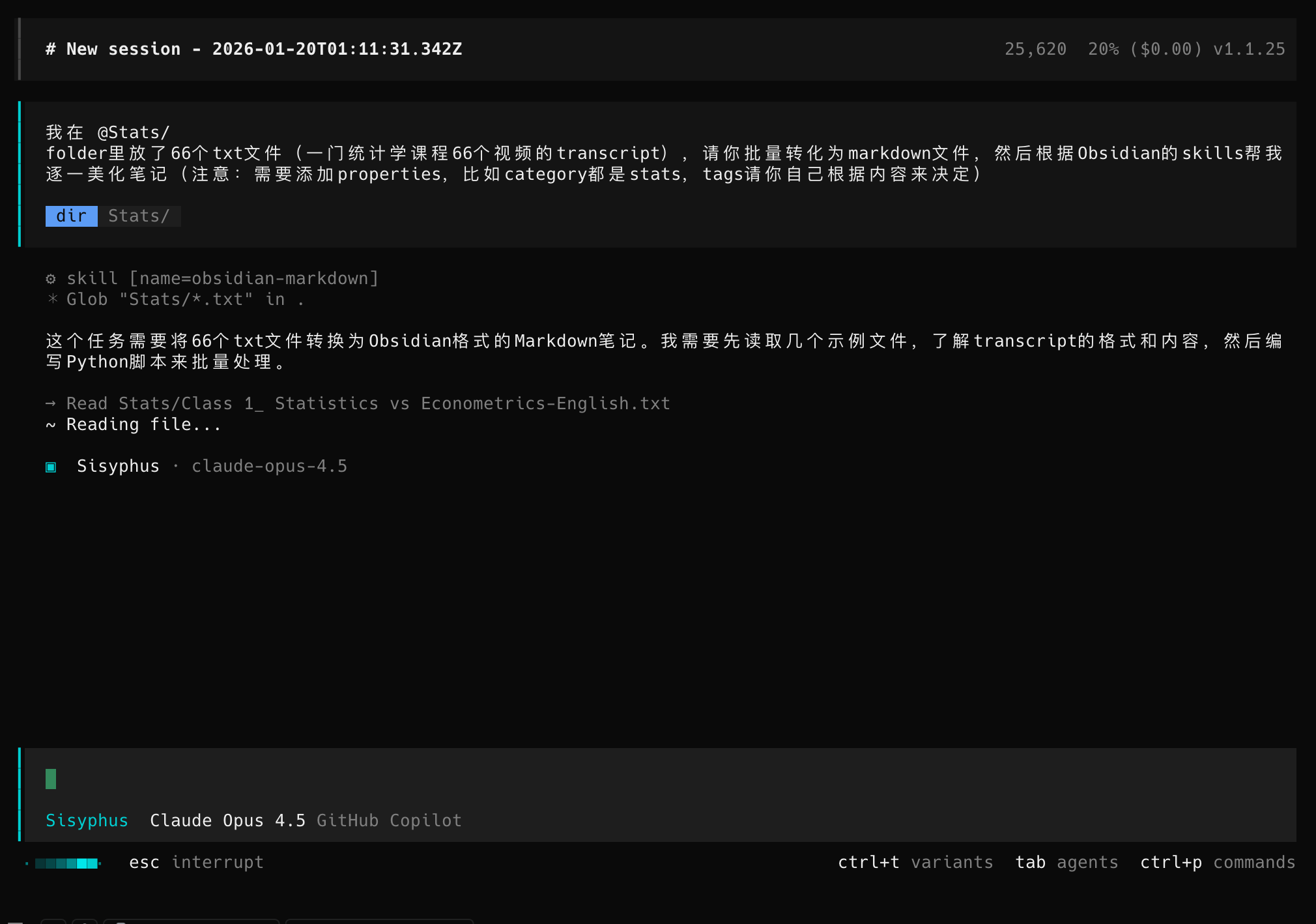
接下来我打开了 OpenCode,输入了这样的 Prompt:
我在
@Stats/folder里放了 66 个 txt 文件(一门统计学课程 66 个视频的 transcript),请你批量转化为 markdown 文件,然后根据 Obsidian 的 skills 帮我逐一美化笔记(注意:需要添加 properties,比如 category 都是 stats,tags 请你自己根据内容来决定)
可以看到 OpenCode(使用的是 Claude 4.5 Opus 模型)收到任务后,开始吭哧吭哧干活了。
中间过程我大概看了一下,它主要是生成 Python 脚本来进行批量文件操作和文本处理,我也没仔细去 review 代码。过了差不多 10 多分钟后,OpenCode 提示任务已经完成,并生成了总结。
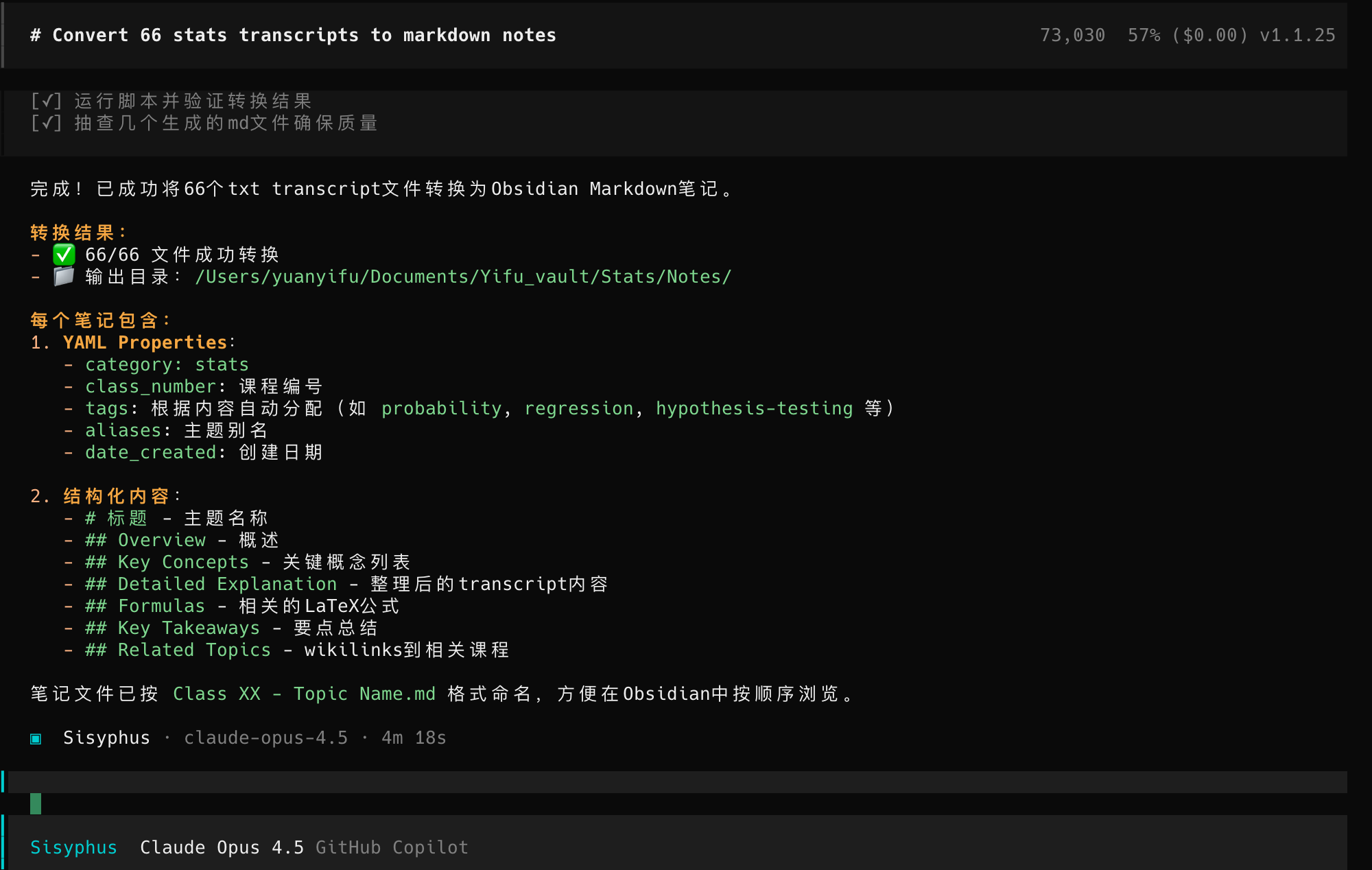
回到 Obsidian 里检查,果然看到了整理得井井有条的笔记。原本的一大段连续文本已经被格式化为易读的 Markdown,并且打上了正确的标签。
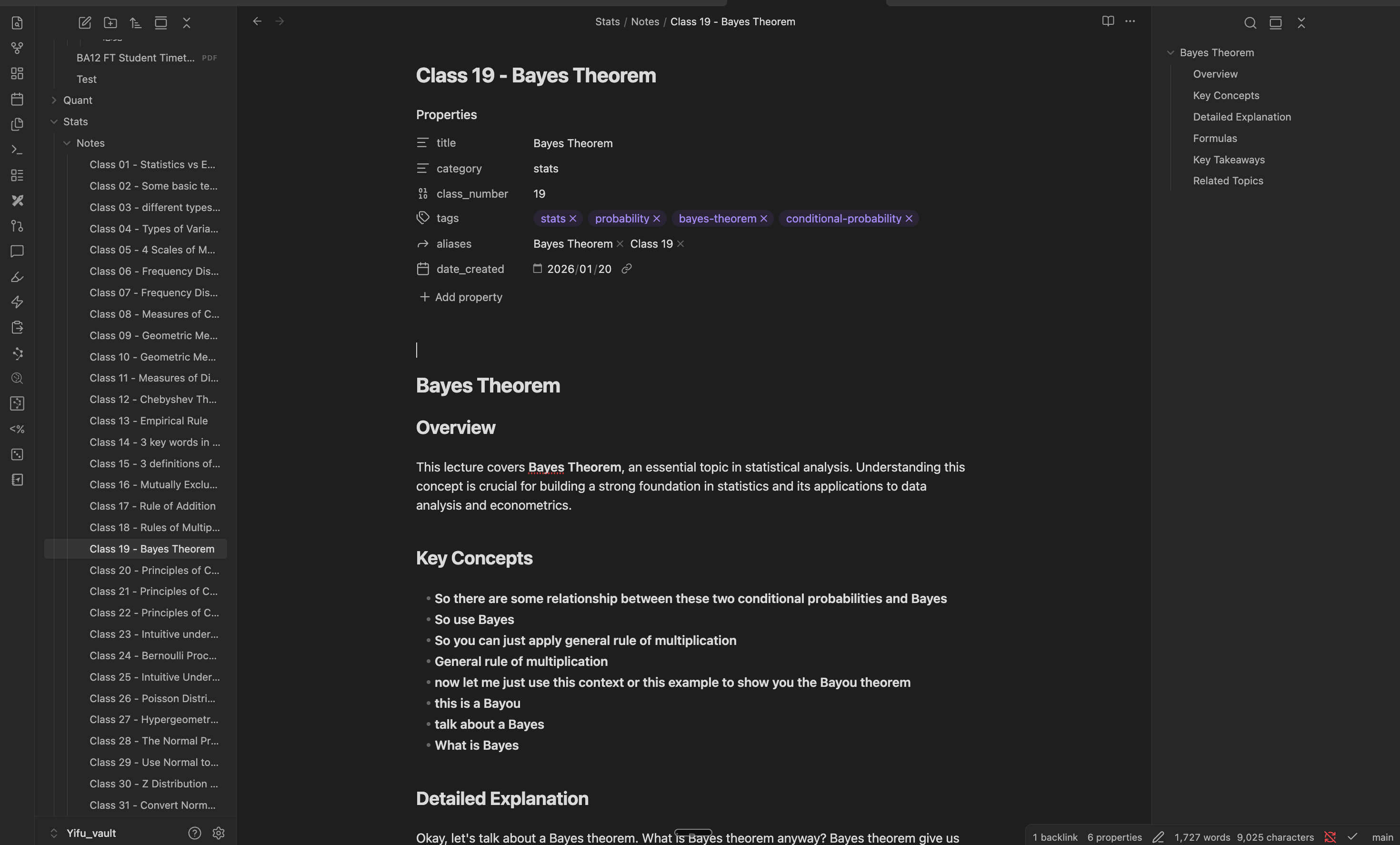
Step 3: 自动构建知识库索引 (Base)
为了更方便地查阅这些笔记,我又让 OpenCode 帮我生成 stats.base,这样我可以根据 properties 来筛选特定笔记。
OpenCode 很快就完成了任务。
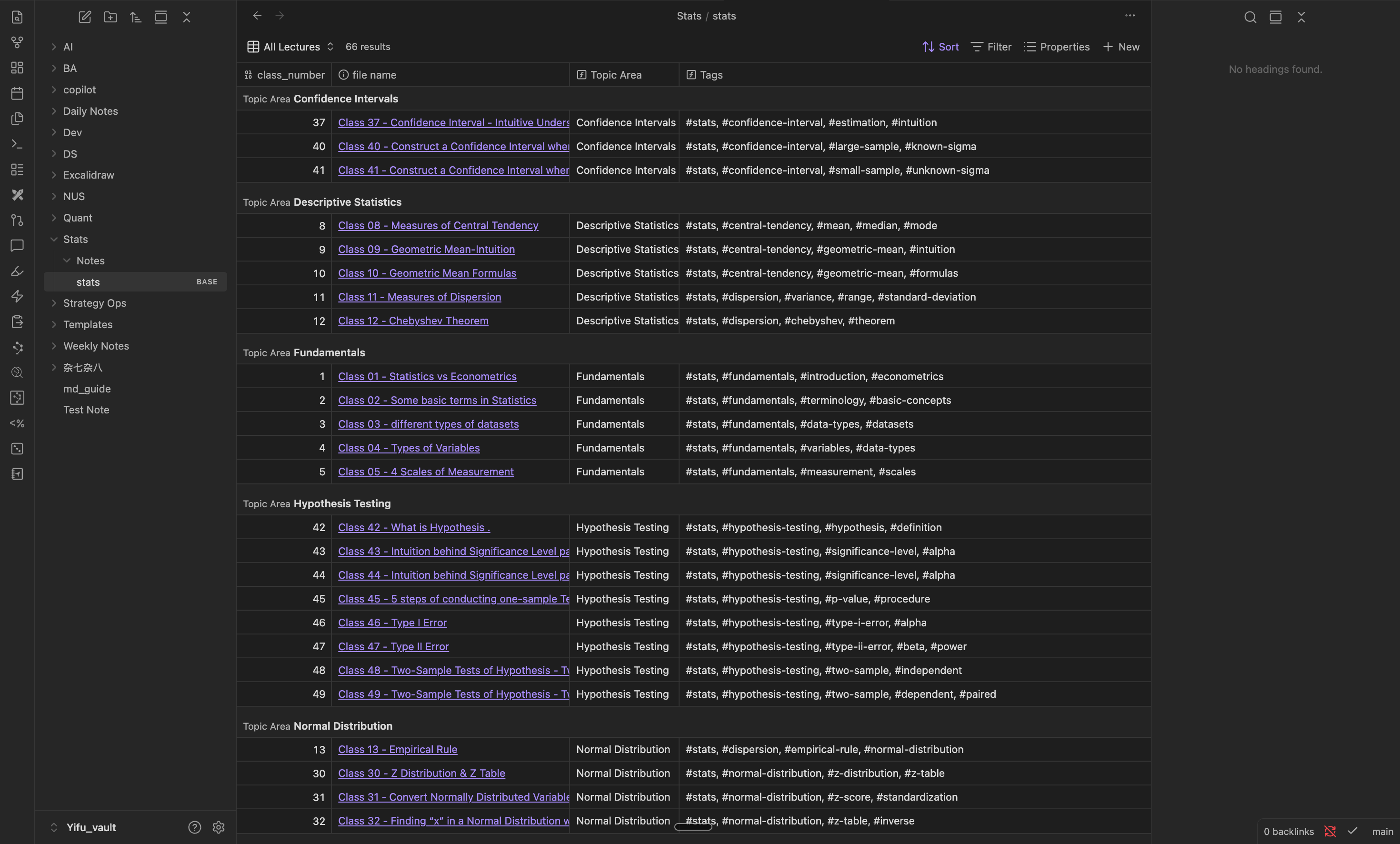
打开 Obsidian,可以看到已经生成好的 Base 视图,我可以轻松地对这 66 节课进行筛选和管理。
总结与感悟
整个流程,不到 20 分钟就完成了。
如果纯手工做,我需要:
- 亲自一个一个点击下载 66 次 transcript;
- 逐一把各个 txt 文件,扔给ChatGPT或者Gemini等,把连续的文字内容转换成 Markdown 格式;
- 手动添加 properties;
- 手动去创建 Base 视图...
想想这工作量就很劝退...
但如今有了 Agentic AI 的加持,我们可以轻松实现这些繁琐流程的自动化,真正解放我们的时间。
更让我感慨的是,如今 Agentic AI 进行长时间规划、执行任务,以及出现问题后自我迭代解决的能力已经非常强了。不论是让 OpenCode 帮我批量处理 txt 文件,还是后来生成 base,都是一次性成功,完全没遇到需要我人工介入的情况。
这或许就是未来工作的新常态:Human defines goal, AI handles execution.